Publications
Publications by categories in reversed chronological order.
2026
-
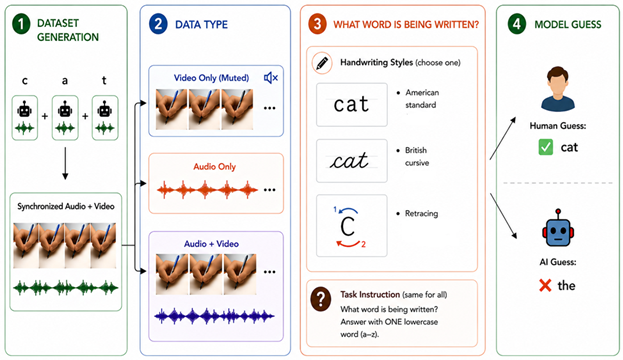 The Unwritten Benchmark: A New Challenge for Multimodal Machine Learning in Abstract Perceptual ReasoningGarima Arya Yadav, Nilay Yilmaz, and Yezhou YangIn CVPR Findings, 2026
The Unwritten Benchmark: A New Challenge for Multimodal Machine Learning in Abstract Perceptual ReasoningGarima Arya Yadav, Nilay Yilmaz, and Yezhou YangIn CVPR Findings, 2026Current multimodal models have demonstrated remarkable proficiency in recognizing static visual and auditory content. However, their capacity for abstract perceptual reasoning, inferring unseen information from dynamic, generative processes, remains a critical and underexplored frontier. In this paper, we introduce The Unwritten Benchmark, a new challenge designed to probe this abstract perceptual and cognitive ability. We define the core task as acousto-kinematic word inference: models must decipher words, across 3 different writing styles, being written solely from the audio of pen scratches and the video of hand movements, without any visible ink trace. Our evaluation results reveal a profound gap between human and machine performance: while human participants achieve high ordered letter accuracy (over 80%), leading Multimodal Machine Learning Models, including GPT-4o and Gemini 2.5-Pro, struggle significantly, failing to even surpass 10%. Furthermore, we identify a paradoxical fusion effect in the models, where providing both modalities often degrades performance rather than improving it. This finding indicates a fundamental breakdown in their ability to synthesize complementary perceptual cues for this cognitive task. These findings highlight a significant challenge for current architectures, pointing to limitations in both cross-modal causal reasoning and the understanding of the micro-kinematics essential for such cognitive and intuitive perceptual reasoning.
@inproceedings{yadav2026the, title = {The Unwritten Benchmark: A New Challenge for Multimodal Machine Learning in Abstract Perceptual Reasoning}, author = {Yadav, Garima Arya and Yilmaz, Nilay and Yang, Yezhou}, booktitle = {CVPR Findings}, year = {2026}, publisher = {OpenReview}, data = {https://huggingface.co/datasets/RiRi-y/unwritten-benchmark}, } -
 MentalBlackboard: Evaluating Spatial Visualization via Mathematical TransformationsNilay Yilmaz, Maitreya Patel, Naga Sai Abhiram Kusumba, and 2 more authors2026
MentalBlackboard: Evaluating Spatial Visualization via Mathematical TransformationsNilay Yilmaz, Maitreya Patel, Naga Sai Abhiram Kusumba, and 2 more authors2026Spatial visualization is the mental ability to imagine, transform, and manipulate the spatial characteristics of objects and actions. This intelligence is a part of human cognition where actions and perception are connected on a mental level. To explore whether state-of-the-art Vision-Language Models (VLMs) exhibit this ability, we develop MentalBlackboard, an open-ended spatial visualization benchmark for Paper Folding and Hole Punching tests within two core tasks: prediction and planning. Our prediction experiments reveal that models struggle to apply symmetrical transformations, even when they correctly predict the sequence of unfolding steps. Additionally, rotations pose a significant challenge to the physical situational awareness of models. The planning task reveals limitations in models’ ability to analyze symmetrical relationships and implement the multi-stage symmetry process, with Claude 4.6 achieving the highest planning score at an accuracy of 14%. The top-performing model, o3, attains a peak performance of 71.6% on the generalization task, which does not require spatial visualization but transfers spatial data; however, it achieves only 25% accuracy on text-based prediction tasks.
@misc{yilmaz2026mentalblackboardevaluatingspatialvisualization, title = {MentalBlackboard: Evaluating Spatial Visualization via Mathematical Transformations}, author = {Yilmaz, Nilay and Patel, Maitreya and Kusumba, Naga Sai Abhiram and He, Yixuan and Yang, Yezhou}, year = {2026}, booktitle = {CVPR 2026 GRAIL-V Workshop}, eprint = {2602.19357}, publisher = {arXiv}, primaryclass = {cs.CV}, data = {https://huggingface.co/datasets/nlylmz/MentalBlackboard}, }
2025
-
 VOILA: Evaluation of MLLMs For Perceptual Understanding and Analogical ReasoningNilay Yilmaz, Maitreya Patel, Yiran Lawrence Luo, and 4 more authorsIn ICLR, 2025
VOILA: Evaluation of MLLMs For Perceptual Understanding and Analogical ReasoningNilay Yilmaz, Maitreya Patel, Yiran Lawrence Luo, and 4 more authorsIn ICLR, 2025Multimodal Large Language Models (MLLMs) have become a powerful tool for integrating visual and textual information. Despite their exceptional performance on visual understanding benchmarks, measuring their ability to reason abstractly across multiple images remains a significant challenge. To address this, we introduce VOILA, a large-scale, open-ended, dynamic benchmark designed to evaluate MLLMs’ perceptual understanding and abstract relational reasoning. VOILA employs an analogical mapping approach in the visual domain, requiring models to generate an image that completes an analogy between two given image pairs, reference and application, without relying on predefined choices. Our experiments demonstrate that the analogical reasoning tasks in VOILA present a challenge to MLLMs. Through multi-step analysis, we reveal that current MLLMs struggle to comprehend inter-image relationships and exhibit limited capabilities in high-level relational reasoning. Notably, we observe that performance improves when following a multi-step strategy of least-to-most prompting. Comprehensive evaluations on open-source models and GPT-4o show that on text-based answers, the best accuracy for challenging scenarios is 13% (LLaMa 3.2) and even for simpler tasks is only 29% (GPT-4o), while human performance is significantly higher at 70% across both difficulty levels.
@inproceedings{yilmaz2025voila, title = {{VOILA}: Evaluation of {MLLM}s For Perceptual Understanding and Analogical Reasoning}, author = {Yilmaz, Nilay and Patel, Maitreya and Luo, Yiran Lawrence and Gokhale, Tejas and Baral, Chitta and Jayasuriya, Suren and Yang, Yezhou}, booktitle = {ICLR}, year = {2025}, publisher = {OpenReview}, data = {https://huggingface.co/datasets/nlylmz/VOILA}, }