Nilay Yilmaz

I am a Ph.D. Candidate in Computer Science at Arizona State University, working under the supervision of Professor Yezhou Yang.
My research centers on evaluating the multimodal abstract reasoning capabilities of vision-language models (VLMs) and large language models (LLMs), with a particular emphasis on spatial visualization and visual analogy problems. These cognitively demanding tasks reflect core aspects of human intelligence, and my goal is to advance our understanding of human cognition by developing models that can mirror such abilities in artificial systems.
I have extensive experience in developing dynamic dataset creation pipelines that include 3D scene construction grounded in physical principles and modular framework structures for flexible task generation. I believe that evaluating model capabilities should go beyond static benchmarks and limited multiple-choice evaluation formats, which fail to reflect a model’s true reasoning ability. Instead, evaluation must be open-ended, comprehensive, and human-aligned to uncover not only what a model gets wrong, but why and how that differs from human reasoning patterns.
Beyond evaluation, I explore training strategies for improving reasoning and generalization in multimodal foundation models. My work investigates modular fine-tuning approaches that decompose complex tasks into reusable skill-based adapters for scalable compositional learning, as well as reinforcement learning methods that adapt human-aligned learning strategies for enhancing transformation-based reasoning in physically constrained environments.
News
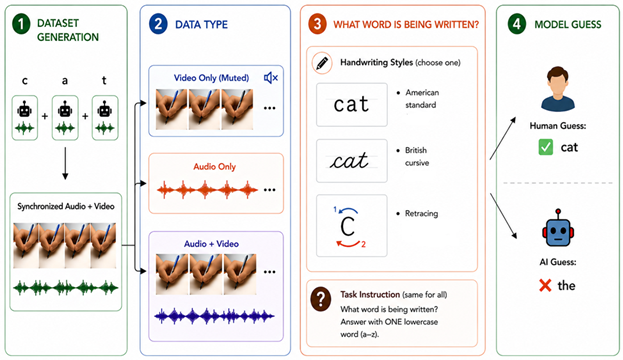
| May 01, 2026 | 🚀 The Unwritten Benchmark is accepted at CVPR Findings 2026! |
|---|---|
| Apr 20, 2026 | 🚀 The MentalBlackboard is accepted at CVPR 2026 GRAIL-V Workshop! |
| Jan 15, 2025 | 🚀 VOILA is accepted at ICLR 2025! |